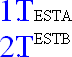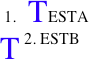For your next presentation, don't use proprietary formats! Use the
OperaShow Generator
to generate HTML and CSS which you can then render in any browser that supports the
'projection' media, such as Opera.
One of the great things about working in the Technology and Research department
at Opera is that I get to play with all kinds of new gadgets and technologies. For
example, last week one of our embedded device customers said that one of our
competitors had tested Opera against their browser and found Opera was slower, and
Opera was asked to prove that this was not the case, so Herman and I were yanked out
of our normal routine and told to test the two products all day until we had an
exhaustive analysis of the two browsers' pros and cons. (We quite happily obliged,
showing that over GPRS, on the test pages that the competitor in question had used,
we out-performed them in page load performance by seconds, sometimes dozens of seconds,
and sometimes sheer orders of magnitude — not to mention that said competitor
had no DOM support, ridiculously limited CSS support reminiscent of desktop browsers
from the late 1990s, and so forth.)
One of the technologies Opera is quite proud of is our CSS media handling. There are
internal versions of Opera that handle handheld,
tv, screen,
projection, print, and even
speech.
And some of these modes have fallbacks, for example if a page is viewed in handheld
mode but has no handheld style, it will fall back on the
SSR (Small Screen Rendering) view.
We also have lovely "content adaption" mechanisms — for example in some builds you can enable
MSR (Medium Screen Rendering) mode,
and then Opera will adapt the formatting of the page to fit your window. I should point out that
this is not at all standards compliant, but it isn't supposed to be: its purpose is to handle
the cases where the page wasn't designed for the device in question, and would be unreadable if
displayed per the specs. Authors who target these devices can rely on standards-based rendering,
since MSR won't trigger unless the page doesn't fit.
One of the medias that Opera supports which no-one else yet supports is projection.
(Mozilla doesn't yet support this, it's bug 120398.)
When you switch to full-screen mode, Opera switches from using your screen styles
to your projection styles. This would be of very limited use, if it wasn't for the
fact that the projection media is a paged media type, much like print,
so properties like page-break-after work!
This lets you do slide shows in HTML with no JavaScript and no :target hacks,
which is pretty cool. Håkon (my boss) wrote a little script that will let you make a three-page
presentation without even touching the markup. As an added bonus, it even embeds the images you
specify using data: URIs, so the page is completely
self-contained.
Here is a summary of the changes since the release of mozbot 2.4:
New modules:
Spell
Checks for spelling mistakes:
<Hixie> Checks for speling (sp?) mistakes.
<mozbot> Suggestions for 'speling': spelling, spalling, sapling, speeling, spieling, spiling, spilling...
ServicesLogin
Enables mozbot to log in to network services such as Nickserv,
K9, Q on Quakenet, or X on Undernet.
Insult
For those of you who mourn the passing of the insult server at the University of Colorado, you'll
be glad that the insult server code was ported to mozbot so that
mozbot can now natively insult people!
Quotes
If you have a MySQL server you can use the Quotes module to
store and retrieve quotes. This module can automatically create the
appropriate tables and so forth when you tell it which server to
connect to.
Currencies
Mozbot can now provide you with up-to-the-minute mid-market
quotes for currency exchange, using the information provided by xe.com.
The bot now supports logging into password-protected IRC
servers.
The "!seen" command now stores its data in a separate file so
that the configuration file doesn't grow without bounds.
You can now tell the bot to stop talking to you by saying
shut up.
Added some protection for loops and annoyance attacks: mozbot
will refuse to say the same thing more than a few times in a
row.
The Converter module now supports time conversions and mass
conversions as well as the already-supported length, temperature and
integer conversions.
The XMLLogger module now logs mozbot parting a channel.
The Greeting module has been greatly improved so that it now is
much more talkative and fun.
The built-in help command is a little more helpful. The help also
now has two styles: compact (the default, as seen in previous
versions), and tidy (the new longer alternate style). You can select
the style you want by changing the "helpStyle" variable:
/msg mozbot vars General helpStyle 'tidy'
/msg mozbot vars General helpStyle 'compact'
Mozbot will now handle nickname changes much more gracefully. It
will also handle nickname clashes and erroneous nicknames in a much
more solid way than the previous version.
Similarly, mozbot is now much better at handling being kicked,
parting a channel, being invited to or told to join a channel, and
quiting IRC. You should no longer see the "I think I'm already *in*
channel #foo!" message. (In fact I guarentee that you will no longer
see it, since I changed the text of the message while I was making it
less likely to appear.)
If you use a bot that has strange restrictions such as not
accepting long IRC names, or requiring correct usernames, mozbot will
now automatically detect the problem and fix it on the fly with no
user interaction.
Mozbot is now able to ignore other bots entirely, and ignore
people talking to other bots. You can enable this using the ignoredUsers
and ignoredTargets
variables, which are described in detail in the INSTALL
file.
Improvements to the mozbot module API: it now supports notices,
modules can now get to the current message queue, and some other minor
changes. The documentation
has also had a number of errors corrected.
The Infobot mozbot module is now slightly more helpful, and for
those of you who are using mozbot primarily for its Infobot
abilities, you can enable the eagerToHelp mode which
will make the Infobot module respond even if asked a question without
a question mark (this mode is on by default for compatibility with
the Infobot bot). For those of
you who just want mozbot for giggles, you can even enable
ridiculouslyEagerToHelp mode which is just that.
(Ridiculous, I mean.)
The Bugzilla module has had significant updates and is now
compatible with the latest version of the Bugzilla software.
The Sheriff module has been updated to handle some common things
people put in their sheriff lines.
We had our (hopefully) final CSS2.1 Editors teleconference today, resolving the last few
CSS2.1 issues that
were raised during Last Call. At last count we had about 272 separate issues. We still have to actually edit
the document, and send out replies and check that everyone who raised an issue is happy with our decisions,
but it is a milestone nonetheless.
The last issue we addressed was related to an issue we resolved early on in the process. (We haven't yet
sent out the e-mail reply on this issue. We will be doing so at some point relatively soon.) Some time ago, fantasai questioned whether
:first-letter should match the contents of :before pseudo-elements. After some
debate, the working group decided that CSS2 was clear on this, and that the main case fantasai had raised (the
case of counters in generated content) was solved by taking list item markers out of :before. (We
agreed that the first digit of the number in a list item shouldn't be styled like a first letter.)
Thus it was decided to leave the draft as is, but to make an editorial clarification in the draft to the
effect that :first-letter should never match list markers. Simple enough, we thought. However,
when it came to trying to write the actual text to go into the specification, it became clear that we weren't
all sure what we had agreed to! In particular, what should happen when you have a list item marker with
list-style-position: inside?
Before deciding on particular rules, we thought we should check what implementations did. I wrote a simple test case:
Doesn't support much of :first-letter in the first place, and doesn't do anything
with the :first-letter on this test.
MacIE 5
Tantek says he couldn't work out how to handle this case, so Tasman (the MacIE rendering engine)
just bails if you try to set :first-letter on a list item with list-style-position:
inside.
WinIE 6
Applies the :first-letter styles to both the marker and the T. This is probably within the
allowed renderings of CSS2, and is readable. Unfortunately, it applies the styling to the numbers, which the working group agreed was not desirable.
Mozilla 1.6
Initially:
After a reflow:
Mozilla's rendering is where things start getting silly. The :first-letter style is
getting applied to the entire first line, and the T on the second line appears twice! If you reflow the page
(for example, resize it, or change the font zoom) then the unstyled T vanishes, leaving the first letter on
the next line. Not, the working group decided, the most optimal of renderings.
Opera 7.50
We couldn't work out exactly what Opera was doing. The first line's rendering makes sense, but the second is quite odd. At no point in the discussion did we ever consider that there might be more than one baseline for the unstyled parts of the rendering.
Safari 1.1
This is probably the most accurate rendering in terms of CSS2, but it is as unreadable as the Mozilla rendering.
The float property on the second line's :first-letter is acting exactly like a float, going all the
way to the left of the line and pushing the other content. This is somewhat at odds with what the working group really
intended float to mean on a :first-letter pseudo-element, namely "make a drop-cap".
Our conclusion? Well, we don't want to force UAs to have to render something in a typographically poor manner, but yet at the same time we don't have any idea what the right way to render this is. All
the ideas we could come up with were flawed in some way. So instead, we took the cop-out solution:
UAs may ignore ':first-letter' on list items with 'list-style-position: inside'.
Making this a "may" instead of a "must" means that user agents are still free to try to do something useful in this case, so if someone does manage to find a useful rendering, they can implement it.
In my last post I explained what
Web specification authors should do with respect to error handling, in my opinion.
What about Web browser implementors and XML?
There is a lot of debate in Web log comments, mailing lists, and forums, about what Web browsers should do. There really shouldn't be. The spec is very clear about this.
As a Web browser implementor, you have two options:
The moment you hit a well-formedness error,
replace the entire page with an error message.
The moment you hit a well-formedness error,
discard everything from that point on, and display
what you got so far, with an error message.
There is no other option. If your browser does anything else, it is violating the specifications. If people want XML to do something else, then they should invent their own language with its own rules — but if you use XML, the above two scenarios are the only allowable scenarios.
(Actually there are a couple of other options, but really they are just variants of the above. First, you are allowed to report more than one error, so long as you don't do anything with any of the content after the first error except for reporting errors. Second, you are also allowed to complain about more than just well-formedness errors: if you are a validating parser you can check for validity as well. For performance and other reasons, these options are never really workable for Web browsers.)
I've been following the recent
burstofpostsaboutwhetherXMLshouldhaverequired
that Web browsers stop processing upon hitting an error (as it does)
or whether it should have let Web browsers recover from errors in
vendor-specific ways (like HTML does) with some amusement, because
asking the question in this yes/no form misses the point:
There is a third, better option.
Since a lot of people don't really understand the problem here, I'm
going to give some background.
What's the point of a specification? It is to
ensure interoperability, so that authors get the same results on every
product that supports the technology.
Why would we ever have to worry about document
errors? Murphy said it best:
If there are two or more ways to do something, and one of those
ways can result in a catastrophe, then someone will do it.
Authors will write invalid documents. This is something that most
Web developers, especially developers who understand the specs well
enough to understand what makes a document invalid, do not really
understand. Ask someone who does HTML/CSS quality assurance (QA) for a
Web browser, or who has written code for a browser's layout engine.
They'll go on at length about the insanities that they have seen, but
the short version is that pretty much any random stream of characters
has been written by someone somewhere and been labelled as HTML.
Why is this a problem? Because Tim Berners Lee, and
later Dan Connolly, when they wrote the original specs for HTML and
HTTP, did not specify what should happen with invalid documents. This
wasn't a problem for the first five or so years of the Web.
At the start, there was no really dominant browser, so browsers
presumably just implemented the specs and left the error handling to
chance or convenience of the implementor. After a few years, though,
when the Web started taking off, Netscape's browser soared to a
dominant position. The result was that Web authors all pretty much
wrote their documents using Netscape. Still no problem really though:
Netscape's engineers didn't need to spend much time on error handling,
so long as they didn't change it much between releases.
Then, around the mid-nineties, Microsoft entered the scene. In
order to get users, they had to make sure that their browser rendered
all the Web pages in the World Wide Web. Unfortunately, at this point,
it became obvious that a large number of pages (almost all of them in
fact) relied in some way on the way Netscape handled errors.
Why did pages depend on Netscape's error handling?
Because Web developers changed their page until it looked right in
Netscape, with absolutely no concern for whether the page was
technically correct or not. I did this myself, back when I made my
first few sites. I remember reading about HTML4 shortly after that
become a W3C Recommendation and being shocked at my ignorance.
So, Microsoft reversed engineered Netscape's error handling.
They did a ridiculously good job of it. The sheer scale of
this feat is awe-inspiring. Internet Explorer reproduces
aspects of Netscape's error handling which nobody at Netscape ever
knew existed. Think about this for a minute.
Shortly after, Microsoft's browser became dominant and Netscape's
browser was reduced to a minority market share. Other browsers entered
the scene; Opera, Mozilla (the rewrite of the Netscape codebase), and
Konqueror (later to be used as the base for Safari) come to mind, as
they are still in active development. And in order to be usable, these
browsers have to make sure they render their pages just like Internet
Explorer, which means handling the errors in the same way.
Browser developers and layout engine QA engineers spend probably
more than half their total work hours debugging invalid markup trying
to work out what obscure aspect of the de facto error handling rules
are being used to obtain the desired rendering. More than half!
It's easy to see why Web browser developers tend to be of the
opinion that for future specifications, instead of having to reverse
engineer the error handling behaviour of whatever browser happens to
be the majority browser, errors should just cause the browser to abort
processing.
Summary of the argument so far: Authors will write
invalid content regardless. If the specification doesn't say what
should happen, then once there is a dominant browser, its error
handling (whether intentionally designed or just a side-effect of the
implementation) will become the de facto standard. At this point,
there is no going back, any new product that wants to interoperate has
to support those rules.
So what is the better solution? Specifications
should explicitly state what the error recovery rules are. They should
state what the authors must not do, and then tell implementors what
they must do when an author does it anyway.
This is what CSS1 did, to a large extent (although it still leaves
much undefined, and I've been trying to make the rules for handling
those errors clearer in CSS2.1 and CSS3). This is what my Web
Forms 2.0 proposal does. Specifications should ensure that
compliant implementations interoperate, whether the content is
valid or not.
Note that all this is moot if you use XML 1.x, because XML
specifies that well-formedness errors should be fatal. So if you don't
want to have this behaviour in your language, don't use XML.